


每周一题,代码无敌~
这次让我们换换口味,讨论一个稍微偏实际一点的问题:
匹配子序列的单词数
给定字符串 S 和单词字典 words, 求 words[i] 中是 S 的子序列的单词个数。
示例
输入:
S = "abcde"
words = ["a", "bb", "acd", "ace"]
输出: 3
解释: 有三个是 S 的子序列的单词: "a", "acd", "ace"。注意
所有在 words 和 S 里的单词都只由小写字母组成。
S 的长度在 [1, 50000]。
words 的长度在 [1, 5000]。
words[i] 的长度在 [1, 50]。
暴力破解法
这周的题目相对简单。从题意上来理解,无非就是 words 数组中每一个单词拿到 S 字符串中去尝试匹配就好。稍微值得注意的是,因为匹配的规则在于不一定是连续子字符串匹配,因此需要考虑每个字母在其中是否全部都存在,Helen 给出了暴力解法:
function numMatchingSubseq(S, words) {
let count = 0;
for (const word of words) {
let index = -1,
_count = 0;
for (const str of word) {
_count++;
const _index = S.indexOf(str, index + 1);
if (_index === -1) break;
else index = _index;
if (_count === word.length) count++;
}
}
return count;
}书香在同样的思路上,利用 JS 的自带 API ,稍微做了一些写法上的优化,让程序看起来更简短了一些:
function numMatchingSubseq(S, words) {
const isSubWord = function (s, word) {
let pos = -1;
for (let i = 0; i < word.length; i++) {
pos = s.indexOf(word[i], pos + 1);
if (pos == -1) return 0;
}
return 1;
};
return words.reduce((count, word) => count + isSubWord(S, word), 0);
}你看出了其中的相同之处了吗?
正则表达式匹配
既然是字串匹配,自然可以通过正则表达式来完成匹配。书香尝试了这一解法:
function numMatchingSubseq(S, words) {
return words.reduce((count, word) => {
const testReg = new RegExp(word.split("").join("w*"));
if (testReg.test(S)) count++;
return count;
}, 0);
}但是,正则匹配花费的计算资源会更高一些,因此这个解法在题目中的超长字串测试用例中,因为超出时间限制而失败了…… 在这里贴出这段代码,仅作为一种思路的参考。
可不可以不那么暴力?
Helen 作为三人行里唯一的女生,自然忍不了动不动就 「暴力破解」的做法 ♀️。因此她换了一个不那么暴力的思路,通过将 words 中的单词按照首字母先排序到一个 「桶」中,将数据进行了预处理,然后在字符串匹配其中字符的的时候,就可以从对应的地方匹配了:
function numMatchingSubseq(S, words) {
const bucket = Array.from({ length: 26 }, () => []);
let count = 0;
for (const word of words) bucket[word.charCodeAt(0) - 97].push(word); // a 的 Unicode 是 97
for (const str of S) {
const list = bucket[str.charCodeAt(0) - 97];
bucket[str.charCodeAt(0) - 97] = [];
for (let word of list)
if (word.length > 1) {
word = word.slice(1);
if (word) bucket[word.charCodeAt(0) - 97].push(word);
} else count++;
}
return count;
}Extra
曾大师的 Go 语言时光,他似乎也很暴力……
func numMatchingSubseq(S string, words []string) int {
count := 0
for i := 0; i < len(words); i++ {
stat := 0
word := words[i]
if len(word) > len(S) {
continue
} else {
for i := 0; i < len(S); i++ {
if word[stat] == S[i] {
stat++
if stat == len(word) {
count++
break
}
}
}
}
}
return count
}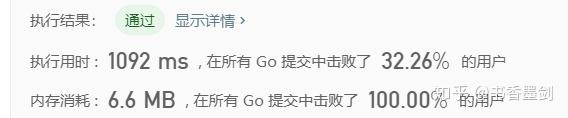
这一次他的时间消耗就没有那么好了,你能看出相比其前面 JS 的两个暴力解法,这次他为什么「失手」了吗?
更多
在这次题目中,三人行不约而同采用了「暴力解法」,并且在一定程度的简单优化上,时间和空间的利用成绩都还不错。事实在,在写代码的过程中,往往也是一个迭代的过程,前期过度地优化有时候反而不如先利用最直观的方式把程序先跑起来,再根据需求和场景条件来进行对应的优化更好。
下周见啦~



