
容器非常了不起。它们允许简单的进程像虚拟机一样运行。这种优雅的背后是一套模式和实践,最终使一切都能正常工作。设计的根源在于层。层是存储和分发容器化文件系统内容的基本方式。这种设计既非常简单,同时又非常强大。在今天的文章中,我将解释什么是层,以及它们在概念上是如何工作的。
容器非常了不起。它们允许简单的进程像虚拟机一样运行。这种优雅的背后是一套模式和实践,最终使一切都能正常工作。设计的根源在于层。层是存储和分发容器化文件系统内容的基本方式。这种设计既非常简单,同时又非常强大。在今天的文章中,我将解释什么是层,以及它们在概念上是如何工作的。

人们常说互联网已经实现了教育民主化:人类知识的总和只需要谷歌搜索即可获取!然而,获取信息只是故事的一半;你还需要能够将原始信息转化为可用的技能。
对于我们很多人来说,这两者之间的差距可能会导致类似于 教程地狱 的情况——不断地做一个又一个教程,却从未觉得自己在取得实质性的进展。
学习如何有效地学习是非常重要的,尤其 是作为一名软件开发人员;学习新知识几乎就是整个工作的全部!如果你能快速掌握新语言/框架/工具,你会比一般的开发人员 更高效 。这有点像超级能力。
在这篇博文中,我将分享我关于学习的心得,并展示我如何快速掌握新技能!
在 Depot,我们专注于为容器镜像提供最快的构建服务。我们主要通过以下方式实现这一目标:
我们将 Depot 运行在 AWS 之上,为每个 Depot 项目使用大型 16 核机器。这些机器使用原生 Intel 和 Arm CPU,避免了多平台镜像的仿真。并且我们使用带有 NVMe SSD 的 Ceph 集群为它们提供分布式缓存存储。这一切都使得执行 RUN 语句变得快速,并使缓存查找和写入变得快速。
对于构建过程本身,除了对构建过程进行许多高级优化之外,我们目前正在对构建过程本身进行许多低级优化。
为了更好地理解其中一些优化,了解 OCI 容器镜像层格式本身很有帮助。
随着 BuildKit 的引入,Docker 的构建后端得到了显著改进,并增添了许多强大的新功能。然而,很多用户并不了解这些新功能。因此,本文将向你介绍那些你绝对应该了解并开始使用的 BuildKit 功能,助你更好地利用 Docker。
在写关于 Git 的文章时,我注意到很多人都在纠结 Git 的错误信息。我已经习惯这些错误信息很多年了,所以花了很长时间才明白大家为什么会困惑:
所以,在这篇文章里,我将逐一分析 Git 的错误信息,列出每条信息中我认为容易混淆的地方,并谈谈当我被错误信息弄糊涂时该怎么做。

我们所有软件工程师每天都在使用 git,但大多数人只接触过最基本的命令,如 add、commit、push 或者 pull,好像还停留在 2005 年。
不过,Git 从那时起引入了许多功能,使用它们能让你的生活变得更轻松,下面就让我们来了解一下最近添加的一些现代 Git 命令。



Michel Weststrate published in CloudBoost · Jun 15, 2016
自几个月前,我已在所有我新写的 React 组件弃用 React 的 setState 。别误会我,我没有弃用本地组件状态,我只是不再用 React 去管理它,并且令人愉快!
使用 setState 对初学者来说很棘手。即使经验丰富的 React 程序员在使用 React 自有状态机制时,也很容易引入微妙的 bug,例如:
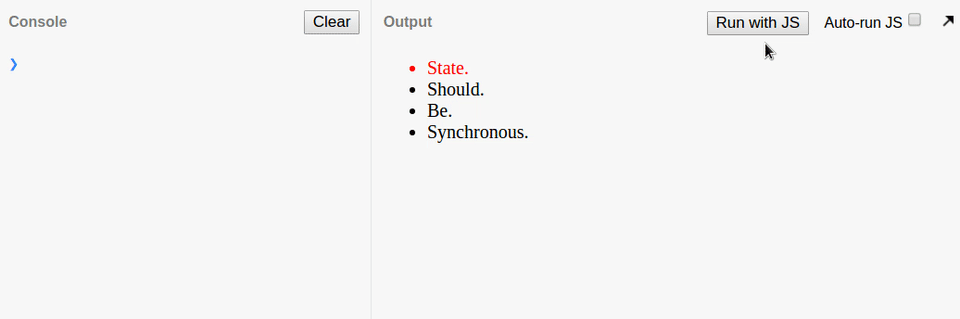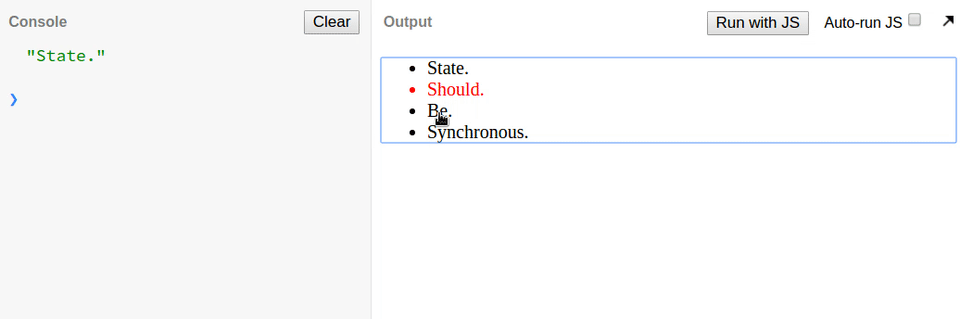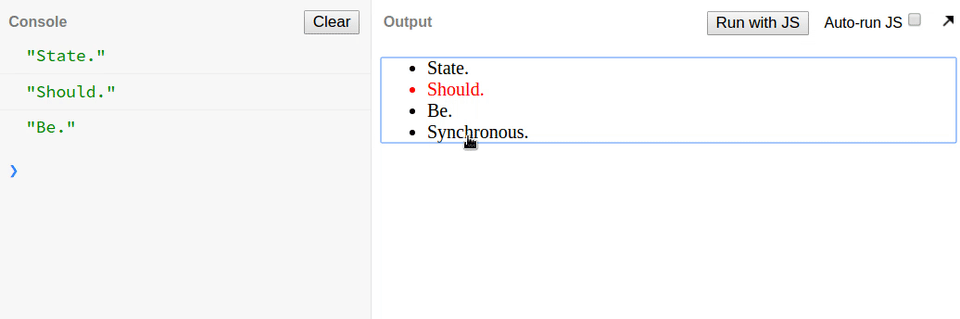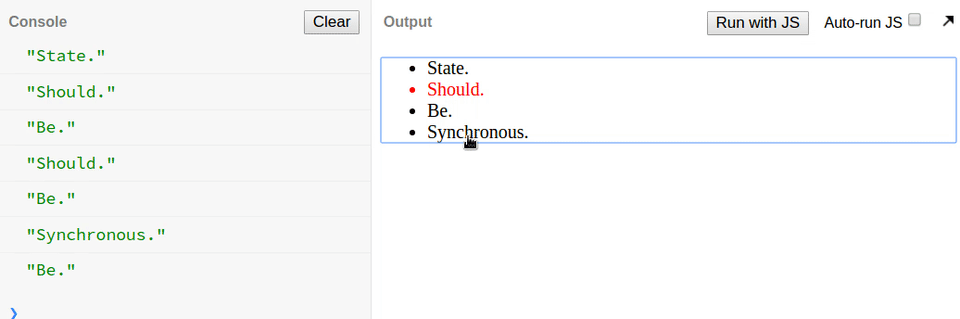
忘记 React 状态是异步的而引入了 bug,日志输出总是在后面一项。
这篇优秀的 React 文档总结了错误使用 setState 的各种情况:

从网络搜索结果中解析数据往往是一件麻烦事。但如果有一种方法能让这一艰苦的过程变得轻而易举呢?让我们尝试一下 OpenAI 的新人工智能模型吧。

Hilman Ramadhan


在本文中,我们将使用 Python、Langchain 和 OpenAI embeddings 构建一个简单但功能强大的书籍摘要器。
用 DALL-E 3 生成上图。
GPT-3 和 GPT-4 等人工智能模型功能强大,但也有其局限性。其中一个重要的限制就是上下文窗口,它限制了模型在同一时间可以考虑的文本数量。这意味着你不能把整本书输入模型,然后期待得到一个连贯的摘要。此外,处理大量文本的成本也很高。
为了克服这些挑战,我们设计了一种既经济又高效的方法。流程如下:
以下是我们如何将长篇大论的书籍转化为简明扼要的摘要:
通过仅在最后一步使用 GPT-4,我们成功地降低了成本。
现在,让我们来分析一下代码和每个步骤背后的原理。
让我们深入代码,一步步构建我们的摘要器。
你好,我是猫哥。这里每周分享优质的 Python、AI 及通用技术内容,大部分为英文。标题取自其中两则分享,不代表全部内容都是该主题,特此声明。
本周刊由 Python 猫 出品,精心筛选国内外的 250+ 信息源,为你挑选最值得分享的文章、教程、开源项目、软件工具、播客和视频、热门话题等内容。愿景:帮助所有读者精进 Python 技术,并增长职业和副业的收入。
微信 | 博客 | 邮件 | GitHub | Telegram | Twitter
本周刊的源文件归档在 GitHub 上,已收获 730+ star 好评,如果你也喜欢本周刊,就请给颗 star 支持一下吧:https://github.com/chinesehuazhou/python-weekly
Update your browser to view this website correctly. Update my browser now



